Identification, Public Policy, and Marijuana Legalization
Making causal inferences from observational data is difficult. It is also necessary to make policy recommendations. If you are so bold as to claim that a policy should be changed based on your findings, then you had better be pretty sure that the relationship you've found is causal, and that it will generalize to the population of interest. Often policy recommendations are made on the basis of correlations which may "suggest" a causal relationship. If a policy change is made based on research where causality hasn't been established, and the relationship turns out to not be causal, it reflects poorly on the researchers involved, on the discipline, and on social science as a whole. Acting more certain than we (social scientists) are about causality gets us into trouble (resulting in articles about how the social sciences aren't very scientific). Why do we feel comfortable making policy recommendations based on correlations? The answer I've often heard is that our recommendations are better than the alternatives. This is an arrogant position (which understandably irritates people outside the academy) and it is not based on any evidence. Perhaps it is a justifiable position in some cases. We should be careful using it though. In any case we should take care to communicate our uncertainty about the causal effect given the data model and our uncertainty about the (often untestable) identifying assumptions (i.e. how credible we think our design is).
I'd like to give an example of one of my failed research projects (there are several), which I started in April of this year, and shelved in November (titled "The Price of Marijuana Legalization," despite the objections of my committee). Hopefully this will be an interesting example of a question about the effectiveness of an important policy that I couldn't answer well enough to make a policy recommendation. If I am going to be perfectly honest, this is also me trying to get a small something out of the many hours I spent on this. For another a great exposition on the difficulties of identification see Luke Keele (one of my advisors) and William Minozzi's 2013 Political Analysis piece, "How Much is Minnesota Like Wisconsin? Counterfactuals in Causal Inference with Observational Data."
The prohibition of marijuana is an important policy issue. Most states still completely prohibit marijuana, though a number of states have decriminalized possession and/or legalized it for medical purposes. Washington and Colorado have begun something closer to full scale legalization. Prohibition costs an enormous amount of money (billions per year) and results in something like half a million arrests a year (> 90% of them for possession). These arrests disproportionately affect historically disadvantaged minorities (blacks and latinos) despite similar levels of consumption amongst whites. Using some unique marijuana transaction data (no longer public), I attempted to estimate the effect of various steps towards legalization (decriminalization, medical legalization, quasi-legalization as in Colorado and Washington) on retail prices. I don't think that retail enforcement has a big effect on prices because the marijuana market is huge (bigger than any other illegal drug) and decentralized in production and distribution. It would seem to be a very difficult market to disrupt. I suspect that most of the expense of black market marijuana comes from the fact that it is produced inefficiently on a small scale (because fixed assets are not attractive when your business is illegal).
I figured that retail level enforcement would be fully present in states where marijuana was completely illegal, present to a lesser degree in decriminalized states, and not present at all in Colorado and Washington. This isn't a readily verifiable claim, since I don't have local level data on marijuana arrests (I think the government is too embarrassed to report the actual numbers). Legal status is then a proxy for retail enforcement, and a bad one at that. Trying to estimate the causal effect of legal status using these binary indicators induces measurement error, probably attenuating the estimated effect (in favor of my hypothesis of no effect), since the legal status in one state might pertain to a different level of retail enforcement than the same legal status in another state. In any case, it is clear that the laws themselves are quite heterogeneous in their provisions, despite being grouped at the state level as "decriminalization," or "legalization."
Legal status is (obviously) not randomly assigned, and it is likely that there are differences between states where marijuana is somewhat legal and fully illegal that confound the relationship between legal status and prices (cultural differences in demand, for example). I used fixed effects, which will remove time-invariant state-specific confounds, but it is possible that some confounds are time-varying (e.g., people move to Colorado because of its liberalism on this issue).
This highlighted another problem, which is that most states have moved towards legalization incrementally. Before Washington legalized marijuana, Seattle had formally de-prioritized the enforcement of marijuana laws (as had Tacoma). Without arrest data it is hard to know how big of a change in enforcement pressure legalization precipitated. Even absent explicit de-prioritization police departments could have anticipated the passage of the law, and allocated resources elsewhere in anticipation. It is hard to know when/if this occurred. Additionally, no states transitioned directly from full prohibition to full legality. In fact, only one state transitioned from full prohibition to decriminalization in the period covered by the priceofweed data (September 2010 to September 2013), Connecticut.
Another problem is the obvious SUTVA violation that results from arbitrage. If a change in retail enforcement in Connecticut decreased price we would expect the price in neighboring states to go down as well (as has obviously been the case with California). NPR did a planet money episode on a marijuana dealer who smuggles marijuana from California to New York City to exploit exactly this sort of price differential. The only thing preventing arbitrage from making prices uniform are transaction costs. By using some splines (a tensor product of thin-plate splines, using Simon Wood's mgcv package) I was able to show that the price gradient changes over time, space, and by marijuana quality. Making any sort of claim about why the price gradient has changed, however, doesn't really seem possible. Since trafficking patterns likely change in response to changes in state level legality, smoothing over space and time is controlling for a post-treatment variable (though there are probably some aspects of trafficking patterns that are confounders rather than effects of changes in legal status).
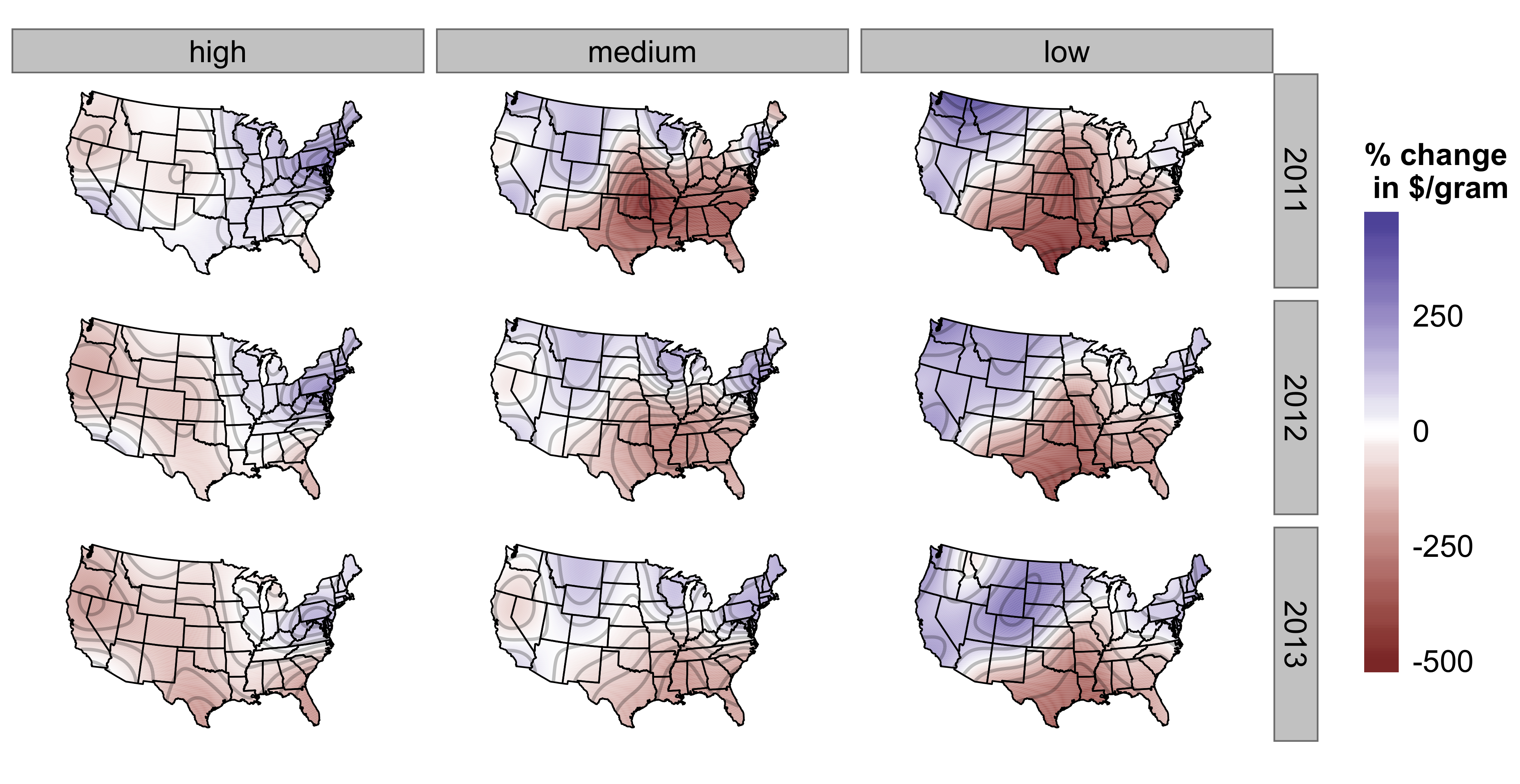
This shows the percent difference in retail marijuana price relative to the mean due to location in space and time. This is based on a generalized additive model of the transaction level natural log of marijuana price per gram, with state-level fixed effects, a factor variable for marijuana quality (high, medium, and low), and a smooth over the quantity purchased.
Lastly, in an economic sense, the causal mechanism is fundamentally unidentified. The price of marijuana is determined by supply and demand, and retail enforcement affects both. So, even if I could identify the effect of enforcement, it wouldn't be clear why enforcement changes prices. See "Unpacking the Black Box of Causality: Learing About Causal Mechanisms from Experimental and Observational Studies" in the American Political Science Review (2011, by Kosuke Imai, Luke Keele, Dustin Tingley, and Teppei Yamamoto), for more on this point.
And so this project is dead, as it should be. Research projects probably don't die often enough. Our discipline (perhaps all of social science) might be better off if many of the things that have been published were instead in an archive folder on the author's computer, or on the author's website with an explanation of how they tried and failed to answer a question that seemed interesting at the time. It seems clear that the reason this isn't the case is because we have strong incentives to publish as much as possible in the highest ranked places we can: jobs, tenure, and promotion depend on it. I don't have any solutions to these problems other than to suggest that quality > quantity.
On request of the owners of priceofweed.com the data I've scraped are no longer publicly available. However, you can contact priceofweed.com to request a copy. You can download the script I wrote to create the map above here. Email me if you want to see any of the other detritus associated with this project.